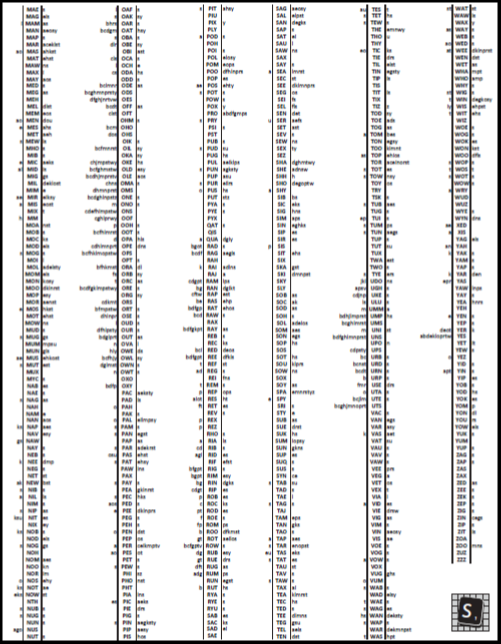
In which I use python to make a cheat sheet and then school my husband at scrabble.[1]¶
The husband and I play a lot of scrabble. We are serious enough about it to use all the two and three letter words (these include "aa", "xu", "cwm" among other nonsense) and the fancy "J", "X", "Z" and "Q" words. But we're not serious enough about it to memorize these words, so we cheat and refer to word lists while we play. There are lots of word lists already out there, but we're obsessively minimalist and didn't want a sheaf of print-outs floating around - we wanted a comprehensive, compact cheat sheet that would fit on just two laminated pages.
The deal with playable words in scrabble is that tournament players use the Official Word List (OWL) while often family or club games use the Official Scrabble Players Dictionary (OSPD). The OSPD is endorsed by Hasbro Inc. and is basically the OWL minus any word that could be considered even mildly offensive. An interesting history of this craziness can be found here and a titillating list of the expurgated words is here.
Every so often new versions of the OWL and OSPD are released, and we wanted our cheat sheet to be current with the most recent OWL3. For some reason I had a really hard time finding an electronic copy of this list anywhere, but it looks like this is a valid one.
We wanted a cheat sheet that was just two pages, each front and back, that we could laminate. We wanted it to have the following things:
- two-to-make-threes (two letter words with their valid front and back hook letters)
- three-to-make-fours
- "J" words up to five letters
- "X" words up to five letters
- "Z" words up to five letters
- "Q" words up to five letters
- "Q" words without a "U"
- vowel dumps (words with at least 66% vowels)
- "U" vowel dumps (words with at least 66% "U"s)
- "I" vowel dumps
- list of the top six and seven-letter-stems for bingos
So this Python project consists of pulling in a complete word list, using it to selectively create the above subsets, writing the individual subsets to file, and then using the cheat sheet to destroy my husband at Scrabble. To skip ahead a bit, here are the outputs that you might be interested in:
- A text file of the full OWL3 word list
- A set of text files for the above word lists
- PDF LINKS IN PROGRESS, NEED TO COMPRESS SIZE
1: But not really because he's better than I am. My strength is spending an inordinate amount of time looking for bingos on my rack and asking if we can "start over" when I don't find one.
Creating the Word Lists in Python¶
Disclaimer: This is newbie python. As in, it is actually the first thing I did while learning Python! You can tell because I included comments for myself like # The "in" operator is implemented for strings. Lol.
Create a complete list of words from an OWL3 text file¶
# Readlines returns a list of lines of file until EOF.
with open("OWL3_Dictionary.txt") as text:
dictionary = text.readlines()
# Strip the newline characters and lowercase each word.
dictionary = [word.strip('\n\r')lower() for word in dictionary]
Here is what a slice of the dictionary list looks like:
dictionary[0:6]
Create more useful subsets of words from the full list¶
I figured we could make the rest of the project cleaner by looping through the dictionary once and pulling out the few subsets that we actually need to work with.
# Loop through the dictionary and create a set of more specific lists
two_words = [] # all the words of length 2
three_words = [] # all the words of length 3
four_words = [] # all the words of length 4
j_words = [] # all the words containing at least one 'j'
x_words = [] # all the words containing at least one 'x'
q_words = [] # all the words containing at least one 'q'
z_words = [] # all the words containing at least one 'z'
for word in dictionary:
if len(word) == 4:
four_words.append(word)
elif len(word) == 3:
three_words.append(word)
elif len(word) == 2:
two_words.append(word)
# The "in" operator is implemented for strings (True if a is a substring of b)
if "j" in word:
j_words.append(word)
if "x" in word:
x_words.append(word)
if "q" in word:
q_words.append(word)
if "z" in word:
z_words.append(word)
Create the 2-to-3 and 3-to-4 Hooks Lists¶
Hooking is a really useful technique in scrabble where you modify a word that's already on the board by adding one or more tiles either to the front or end of the word. The two and three letter words often have a lot of allowable single-letter hooks so it is helpful to have a list of the same. We can use the two, three and four-length lists to make an array which holds the information about what are valid hooks for each two-letter word, and another array to do likewise for three-letter words. For instance, the two-letter-hooks array will consist of a single row for each two-letter word, where the row has three elements: the first element is valid prefixes, the second element is the two-letter word and the third element is valid suffixes.
def find_hooks(short_words, long_words):
'''Take as an input two lists of words, the first being the list of smaller-sized words,
the second being the list of larger sized words to get hook letters from. Outputs a list
of lists with this hook information.'''
hooks_array = []
for short_word in short_words:
prefixes = [long_word.replace(short_word, "") for long_word in long_words if short_word == long_word[1:]]
suffixes = [long_word.replace(short_word, "") for long_word in long_words if short_word == long_word[0:-1]]
hooks_array.append([prefixes, short_word.upper(), suffixes])
return hooks_array
two_to_make_threes = find_hooks(two_words, three_words)
three_to_make_fours = find_hooks(three_words, four_words)
Here is what an entry (row) in the output arrays look like (in this case, the two-letter word is "Aa" which can be hooked with "b" to make "Baa" or back-hooked with "h", "l" or "s" to make "aah", "aal" and "aas".
two_to_make_threes[0]
Write the hook lists to file¶
The above arrays are nice to have in case we ever want to manipulate this information to make e.g. a game for learning the hooks. For now though we want to output them in a text file in a useful format.
# For writing to file the prefixes will be collapsed into a string, and likewise for the suffixes.
def print_hooks(filename, hook_array):
with open(filename, 'w') as text:
# The join method for strings concatenates all the string elements in the input sequence by
# gluing them together with the string on which the method is called.
compressed_array = ["".join(row[0]) + " " + row[1] + " " + "".join(row[2]) for row in hook_array]
text.writelines(["%s\n" % row for row in compressed_array])
print_hooks("Two_to_Make_Threes.txt", two_to_make_threes)
print_hooks("Threes_to_Make_Fours.txt", three_to_make_fours)
Create the "J", "X", "Z" and "Q" lists¶
These guys are the "money tiles" - they are all high point and somewhat difficult to play. For this reason it's helpful to have a list of the shorter words which use them. Here we cull the full X, J and Z lists to restrict to words of length five or less, and then we sort them by length first and alphabetization second (meaning all the length two words will be first in alphabetical order, etc). I will write a function to do these steps, as well as writing the list to file.
def pointer_lists(wordlist, filename):
'''Create and write to file sorted (length, then alphabet) word lists.'''
shortlist = [word for word in wordlist if len(word) <= 5]
# The default sort behavior for a list of lists is sort on first element, then second etc.
# Our sorting key returns a list with first element being word length and second element being the word.
shortlist.sort(key=lambda item: (len(item), item))
with open(filename, 'w') as text:
text.writelines(["%s\n" % word for word in shortlist])
pointer_lists(j_words, "Short_J_Words.txt")
pointer_lists(x_words, "Short_X_Words.txt")
pointer_lists(z_words, "Short_Z_Words.txt")
pointer_lists(q_words, "Short_Q_Words.txt")
Create the Q-without-U list¶
Now we want to make a list that is Q words that have no "u" in them! There are not many of these so we will not restrict to length five.
q_without_u = [word for word in q_words if "u" not in word]
q_without_u.sort(key=lambda item: (len(item), item))
with open("Q_without_U_Words.txt", 'w') as text:
text.writelines(["%s\n" % word for word in q_without_u])
This is kind of a fun list, here are some members:
q_without_u[5:12]
Create the Vowel Dumps¶
A common but rather unfortunate situation is to be staring at a rack with mostly vowels. All the vowels are only one-point tiles, so it is hard to score with such a rack and often you just try to play off a large number of them. The vowel dump list is a list of words which have length six or less and which each contain at least 66% vowels (the exception is three-letter words which instead must contain 100% vowels... there is only one of these). That means for a two or three-letter word it must be all vowels, for a four-letter word it must be three vowels, and for a five-letter word it must be four vowels. We will also want to make specific "I" dumps and "U" dumps which are defined as words containing at least 66% "U"s or "I"s respectively.
A nice modular way to proceed is to make a general function that tells you whether the fractional content of set of specific characters is above a certain threshold for any word. For instance in making the vowel dump list the key characters will be "a" "e" "i" "o" and "u" and the threshold will be 66%.
def wordcontent(word, matchlist, minfraction):
'''Determines if the percentage of characters which are in a "match list" in a
given word is greater than or equal to a certain percentage.'''
matches = [(char in matchlist) for char in word]
percentage = sum(matches)/float(len(word))
return True if percentage >= minfraction else False
# Pull out only words have 66% or more vowels and are length six or less, and sort by length/alphabetical.
vowels = ["a", "e", "i", "o", "u"]
voweldump = [word for word in dictionary if wordcontent(word, vowels, 0.66) and (3 < len(word) <= 6)]
voweldump.append("eau") # handle the one three-letter word exception!
voweldump.sort(key=lambda item: (len(item), item))
with open("Vowel_Dumps.txt", 'w') as text:
text.writelines(["%s\n" % word for word in voweldump])
Here is what a slice of the vowel dump list looks like... lots of words you probably don't recognize.
voweldump[65:73]
Now we can use the same wordcontent function to make the more specific "U" and "I" vowel dump lists:
idump = [word for word in dictionary if wordcontent(word, "i", 0.50) and len(word) > 2]
idump.sort(key=lambda item: (len(item), item))
with open("I_Dumps.txt", 'w') as text:
text.writelines(["%s\n" % word for word in idump])
udump = [word for word in dictionary if wordcontent(word, "u", 0.50) and len(word) > 2]
udump.sort(key=lambda item: (len(item), item))
with open("U_Dumps.txt", 'w') as text:
text.writelines(["%s\n" % word for word in udump])
udump[0:10]
idump[0:8]
That's it - all the lists I wanted on the cheat sheet now outputted as newline-delimited text files.
Making the Cheat Sheet in Adobe Illustrator - blergh!¶
This part was necessary, but also kind of sucked. The hook lists were especially problematic - I ended up importing the text files into Excel to get columns, then copy/pasting that into Word and doing all sorts of formatting gymnastics to get the columns to look how I wanted, then exporting that to a PDF and opening it in Illustrator. For the other word lists I want to mention the revelatory Text > Text Area Options menu in Illustrator that lets you format text into columns. Anyway, you can check out the pics below.